Summary
| Area | Updates |
|---|---|
| Platform | Secret References; weekly rate and budget windows (rpw) and endpoint-scoped rate limits |
| Observability | GCS log storage via GCP WIF from AWS; analytics for archived workspaces and workspace slugs in filters |
| Guardrails | Zscaler AI Guard; Akto Agentic Security; Bedrock Guardrails customHost; required metadata key–value guardrails |
| Models and providers | DeepInfra; DeepSeek; Vertex metadata labels, enterprise web search, AWS–GCP WIF; Azure AI Foundry rerank; Bedrock batch embeddings |
Platform
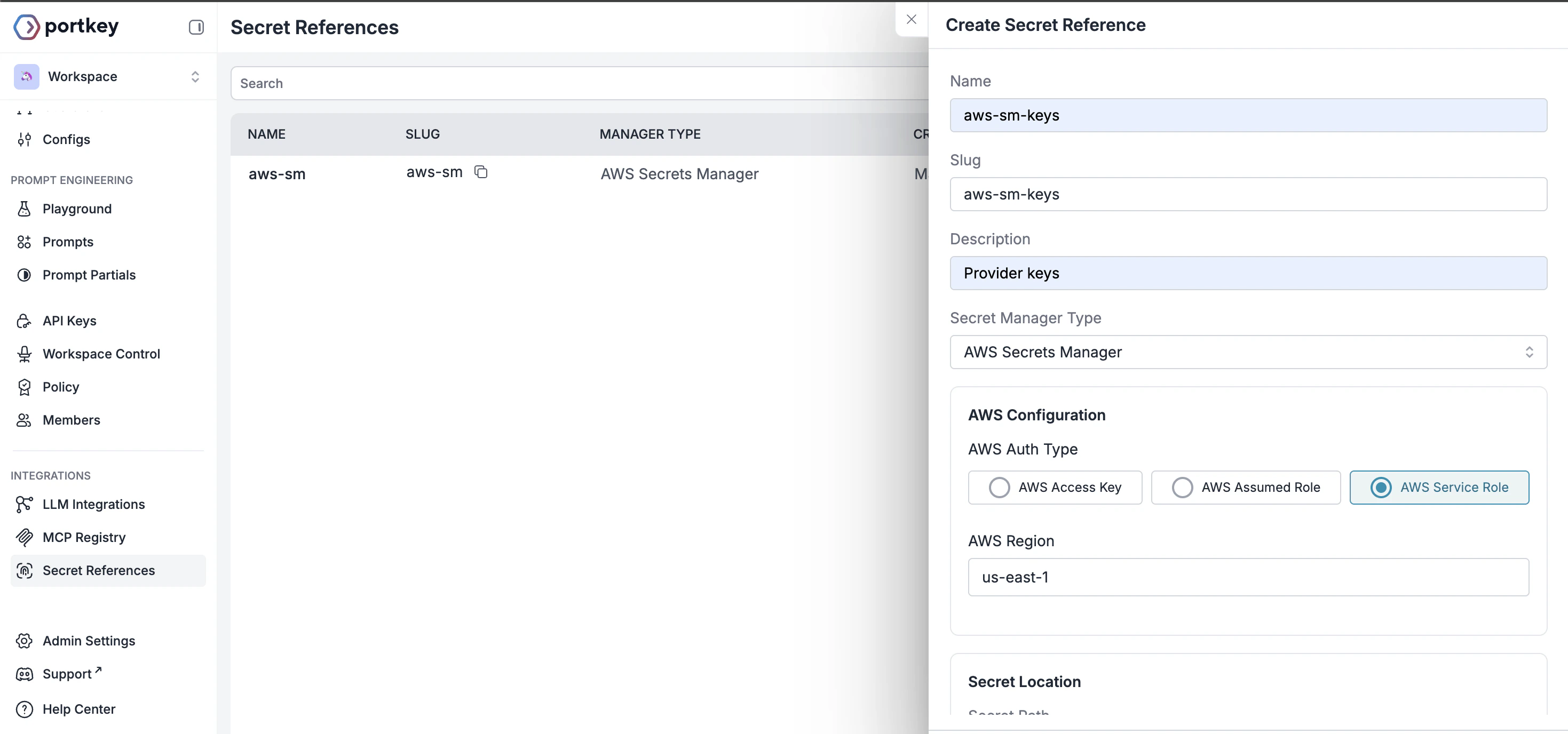
Secret References
Instead of entering keys directly in Portkey, use Secret References to point Portkey at credentials stored in your external vault (AWS Secrets Manager, Azure Key Vault, or HashiCorp Vault). Map integrations and virtual keys withsecret_mappings so Portkey fetches values at runtime.
Weekly and endpoint-scoped rate limits
You can now set budget and usage limits on weekly windows (rpw), so caps align with how teams plan and review spend week over week, not just minute-by-minute or monthly aggregates.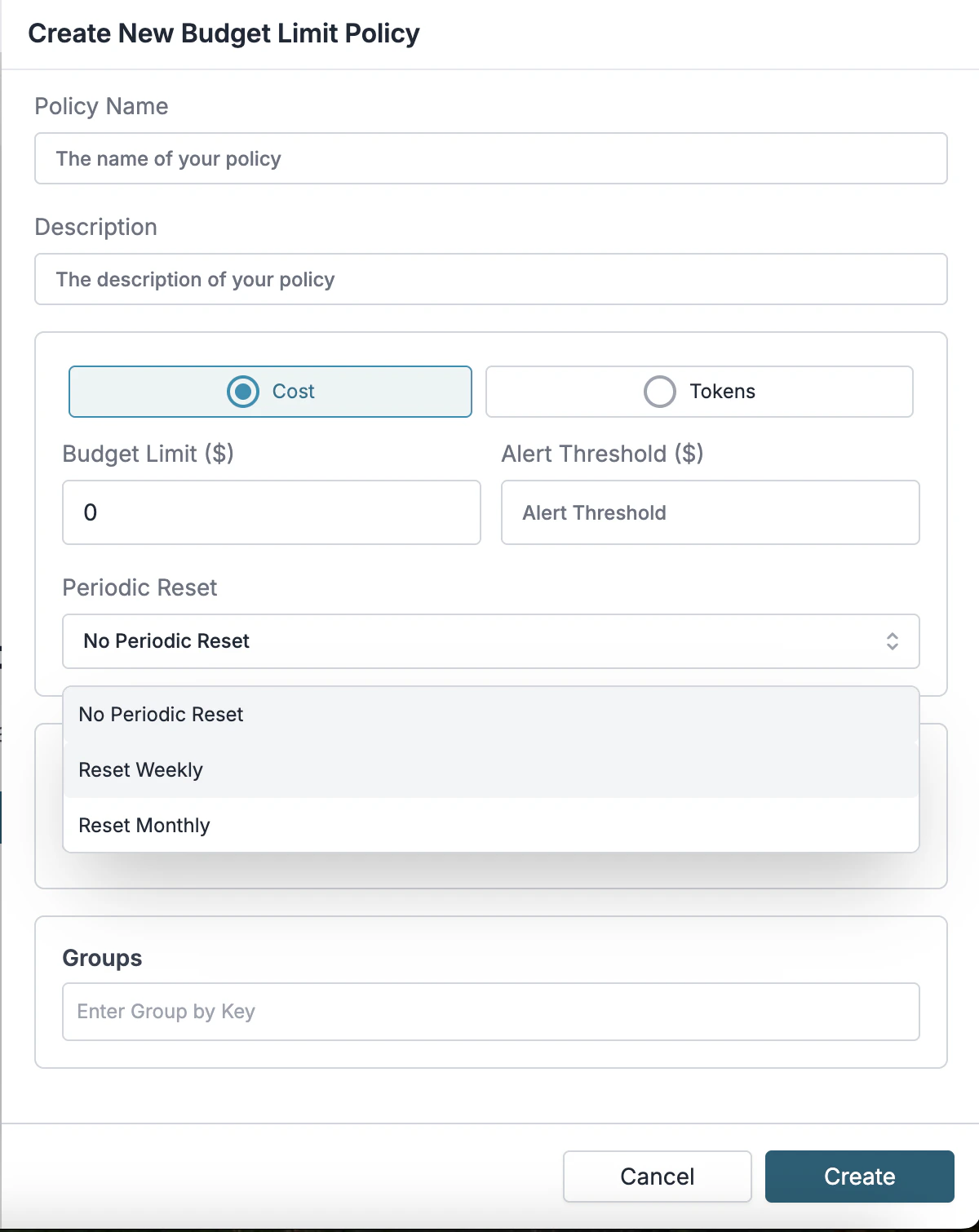
Observability
Log storage: GCP workload identity from AWS
When the gateway runs in AWS but you write logs to Google Cloud Storage, configureGCP_WIF_AUDIENCE and GCP_WIF_SERVICE_ACCOUNT_EMAIL so the gateway authenticates through GCP Workload Identity Federation (gcs_assume style flows), without long-lived GCP keys sitting in AWS.
This keeps cross-cloud log delivery out of static secrets in config or images.
See hybrid GCP deployment & gcs_assume log storage
Analytics for archived workspaces
Organization admins and owners can include archived workspaces in analytics graphs, groups, and summaries. Saved filters also accept workspace slugs alongside IDs. This keeps reporting and automation stable as teams wind down or rename workspaces. See analytics exportGuardrails
Zscaler AI Guard
Connect Zscaler AI Guard so Zscaler Detections Policies apply to LLM inputs and outputs throughbeforeRequestHook and afterRequestHook, with a required policyId and optional timeout (default 10000 ms).
This reuses the same policy class your security org already operates.
See how to connect Zscaler AI Guard
Akto Agentic Security
Add Akto as a guardrails partner to scan LLM inputs and outputs for threats such as prompt injection and sensitive data leakage, with hooks and a configurable timeout (default 5000 ms). This aligns agentic traffic with how you scan other production services. See how to add AktoBedrock Guardrails custom host
SetcustomHost on the Bedrock guardrail plugin so checks hit private or regional Bedrock-compatible endpoints, not only default public URLs.
This keeps guardrail evaluation on private or regional endpoints your network and security policies already trust, instead of the default public Bedrock URLs.
See how to configure Bedrock Guardrails
Required metadata key–value guardrails
You can configure guardrails to enforce required metadata on every request. If any required field is missing or invalid, the gateway blocks the request before it ever reaches the model. Learn moreWhy customers choose Portkey!

Models and providers
- DeepInfra
- Tool calling with
tools,tool_choice, andparallel_tool_calls. - Completions and embeddings endpoints alongside chat.
- Tool calling with
- DeepSeek
deepseek-chat:tools,tool_choice, andstream_options.deepseek-reasoner: mapsreasoning_effortto thinking mode and returnsreasoning_contentin streams.- Streaming usage honors
stream_optionsfor reporting.
- Bedrock: Batch inference supports embeddings as well as chat completions, so you can run large embedding jobs with the same batch patterns you use for chat.
- Vertex AI
- Portkey metadata maps to Vertex resource labels.
- Enterprise search grounding via
enterpriseWebSearch/enterprise_web_search(cost attribution separate from standard Search grounding). - AWS workloads reach Vertex with AWS–GCP WIF (
GCP_WIF_AUDIENCE,GCP_WIF_SERVICE_ACCOUNT_EMAIL).
- Azure AI Foundry rerank
- Cohere rerank models (e.g.
cohere.Cohere-rerank-v4.0-pro). - Gateway strips the
cohere.prefix for the provider.
- Cohere rerank models (e.g.
Bug fixes and improvements
- OpenTelemetry: GenAI semantic spans follow semconv 1.40.0 for inference and embeddings, with OTEL exporter support for guardrail flows and custom resource attributes—making downstream APM and tracing easier to standardize on.
- Header forwarding: the gateway no longer forwards
x-portkey-forward-headxers, preventing header-forwarding loops and obscured provenance in chained setups. - Streaming usage: usage metadata is passed through for the Responses API and DeepSeek (and related routes) so streaming responses stay consistent for cost and usage reporting.
- Together AI: cost logging for video generation requests.
- Anthropic / OpenAI-style image routes:
stricttool parameters andresponse_formathandling for non–DALL·E image models where applicable. - Budget tracking: fixes to avoid double-counting and data loss in the budget pipeline (where applicable in this release window).
Resources
Which AI Model are companies actually Paying For in 2026?
Over 1 trillion AI tokens pass through Portkey every day, The Neon Show talks with Rohit Agarwal (Portkey) about which models enterprises actually pay for in production and what changes after the prototype ships.- Blog: LLM Deployment Pipeline Explained Step by Step
- Blog: What is AI lifecycle management?
- Blog: MCP vs Function Calling
- Blog: 1 Trillion Tokens and the Death of the Chatbot
Community Contributors
Shoutout to Pinji Chen (Tsinghua University) for identifying an edge case with custom host and header forwarding;grateful for contributors who help us improve!Support
Need Help?
Open an issue on GitHub
Join Us
Get support in our Discord